


Data that is accessed together should be stored together. A document should not acceed the 16MB size limit.
A lot of developers simply jump into modelling the data in MongoDB without understanding it's design patterns and that leads to scalability and cost issues , I'm guilty of the same mistakes in the past. Thus, I have compiled a list of anti-patterns that will prevent you from committing these mistakes and help you scale your database optimally.
These are:
Permalink1. Unnecessary indexes
Indexes help MongoDB query efficiently, otherwise it will scan the whole collection for a particular query which is slow and resource intensive. But, it's important to not have indexes that you will never use because indexes consume space and impact write performance. MongoDB uses WiredTiger Storage Engine which keep a file for each collection and a file for each index in it's RAM. Each collection should have less than 50 indexes.
Permalink2. Large Number of Collections
A Database replica set should not have more than 10,000 collections. You should drop empty collections and stay away from creating collections which are primarily made of indexes. You should use MongoDB atlas or it's GUI compass to get stats.
Permalink3. Large arrays
Indexes perform slower on larger arrays and unbounded arrays can make the document larger than 16 MB. Let's look at an example:
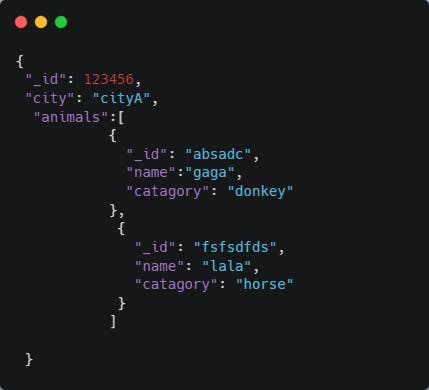
Above pattern is bad as the animals array is unbounded if the number of animals is huge. The fix:

Permalink4. Bloated documents
WiredTiger stores frequently accessed documents in cache(called as "working set") and if your documents are bloated that means it will hamper performance. Better way is to separate data into different collections which is not accessed together.
This is how WiredTiger cache is calculated:
50% of (RAM- 1GB), or
256 MB
Let's look at an example:
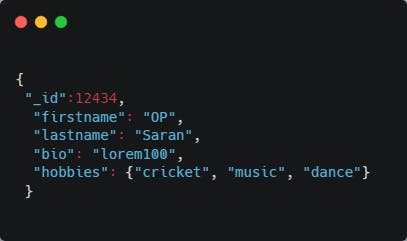
Now, let's say the home page displays only names of authors, we don't need to put every detail about the author in the same collection as it will fill the working set with few documents and homepage query will need to access disk which is a slow process.
The fix:
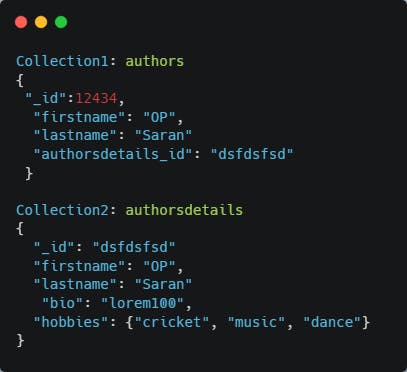
Permalink4. Case-Insensitive queries without case-insensitive index
Case-insensitive queries sometimes gives us unwanted results, because the index on which we are performing the query is case-sensitive. To solve this problem, you might think of using regex but regexes are slow to perform and don't utilize the benefits of indexing. Enter collation:
Collation allows users to specify language-specific rules for string comparison, such as rules for lettercase and accent marks.
If we set the collation at the time of collection creation, we won't need to specify it during the query. collation strength is the important parameter and for case-insensitive queries, it needs to be set as 1 or 2. To read more on this->
PermalinkAbout BoomLabs:
BoomLabs is an agency providing new age web solutions. Our services include:
- Web Design and Development
- SEO (For SaaS and E-commerce businesses)
- Content writing using AI.